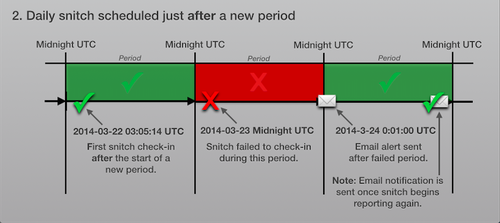
On Friday, March 6th we had a major outage caused by a loss of historical data.
During the outage we failed to alert on missed snitch check-ins and sent a
large number of erroneous failure alerts for healthy snitches. It took 8 hours
to restore or reconstruct all missing data and get our systems stabilized. I am
incredibly sorry for the chaos and confusion this caused.
So what happened?
On March 6th at 9:30 EST we deployed a change that decoupled two of the
models in our system (historical periods and check-ins). At 9:45 EST a user
triggered an unscoped deletion of all historical period records when they
changed the interval of their snitch.
We were alerted at 9:50 EST and immediately disabled our alerter process to
avoid further confusion. We began diagnosing the cause and at 10:50 EST
deployed a fix for the unscoped delete. Our next step was to restore the
missing data from our backups. We decided to keep the system live and to use a
slower but more accurate process to restore the data due to possible conflicts
created by keeping the system running.
At 17:30 EST we finished the restoration of most of the historical data and ran
a set of data integrity checks to ensure everything was in a clean state. We
sent out one final set of “reporting” alerts for any snitches that were healthy
but thought to be failed.
How did this happen?
We use a pull request based development process. Whenever a change is made it
is reviewed by another developer and then merged by the reviewer. It’s common
to make several revisions to a change before it is merged.
In this case, the unscoped deletion was introduced as part of implementing a
suggestion to reduce the number of queries made during an interval change. When
making the change the scoping to only those periods for a snitch was
accidentally removed. The code was reviewed but the scoping issue was missed on
final review.
Additionally, we have an extensive test suite in place that gives us confidence
when we make large changes to the system. Our tests did not uncover this issue
since the unscoped delete satisfied our testing conditions.
Our next steps
1. We have reviewed our use of destructive operations that could be prone to
scoping issues (e.g. Model.where(…).delete_all) and have found that this was
the only instance of it left in our codebase.
2. We have reviewed our tests around destructive behavior and have added
cases to ensure they only affect the records they should.
3. Our restore and recovery process took much longer than we would like. We
developed a set of tools for checking data integrity while we waited for the
restore to finish and we will be fleshing these out further and making them a
part of our normal maintenance routine. Lastly we will be planning and running
operations fire drills to improve our readiness for cases like this.
Summary
Monitoring failures can mean lost sleep, lost time, and added stress to an
already stressful job. As an operations person I am well aware of the trouble a
malfunctioning system can cause. I am very sorry for the chaos and confusion
caused by our failings. We very much see Friday’s issues a failure of our
development process and are taking the steps to improve that process.
Should we have future issues the best place to get notified is to subscribe to
notifications at status.deadmanssnitch.com or to follow us on twitter.
- Chris Gaffney
[i] Collective Idea